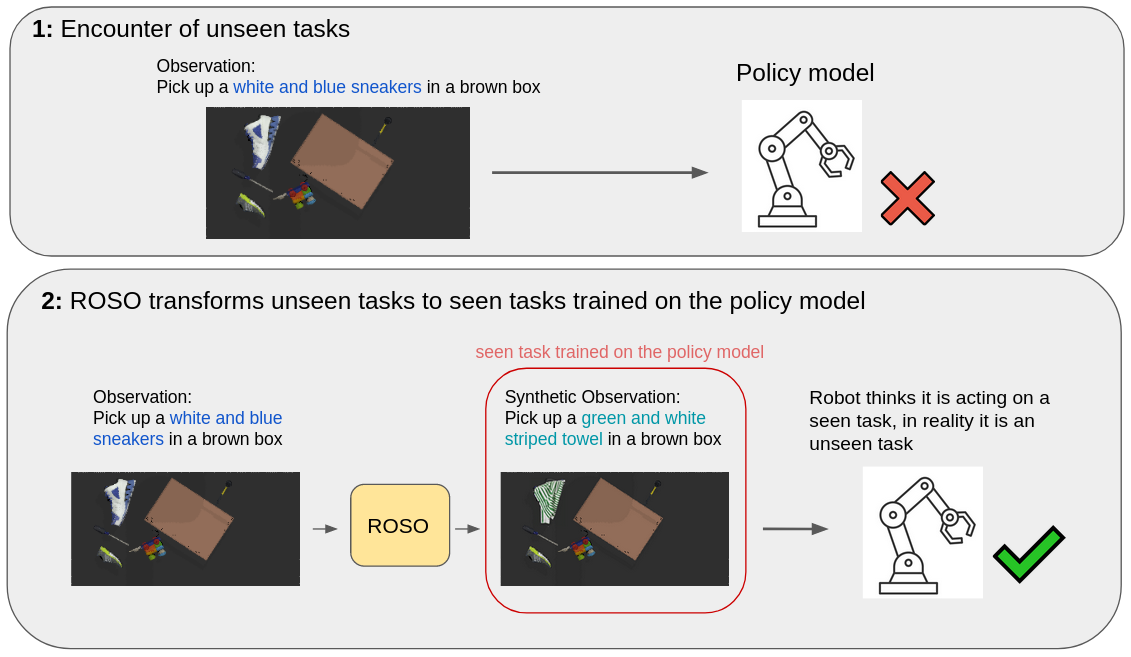
In this paper, we propose the use of generative artificial intelligence (AI) to improve zero-shot performance of a pre-trained policy by altering observations during inference. Modern robotic systems, powered by advanced neural networks, have demonstrated remarkable capabilities on pre-trained tasks. However, generalizing and adapting to new objects and environments is challenging, and fine-tuning visuomotor policies is time-consuming. To overcome these issues we propose Robotic Policy Inference via Synthetic Observations (ROSO).
ROSO uses stable diffusion to pre-process a robot's observation of novel objects during inference time to fit within its distribution of observations of the pre-trained policies. This novel paradigm allows us to transfer learned knowledge from known tasks to previously unseen scenarios, enhancing the robot's adaptability without requiring lengthy fine-tuning.
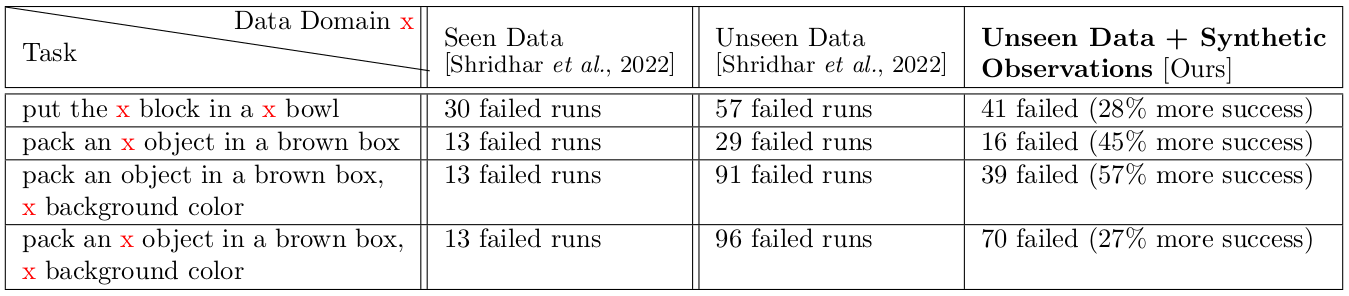
Our experiments show that incorporating generative AI into robotic inference significantly improves successful outcomes, finishing up to 57% of tasks otherwise unsuccessful with the pre-trained policy.
The synthetic observations creation by our pipeline (ROSO) can be split into two aspects: instruction modification and image modification, similar to ROSIE. We obtain the initial language instruction and visual observation to produce automated object masking are fed into policy. The target pick/place object in the visual observation is then altered to a new object utilizing masking and inpainting.
Our aim is to replace a target that the CLIPort trained policy has never interacted with in training time, with one it has interacted with. For example, if the policy was trained to pick and place red cubes but had never been trained on blue cubes, upon encountering a blue cube, the masking would identify the novel cube, and inpainting would replace it with a red cube of the same dimensions. In addition, we alter the initial language instruction into an altered instruction which now makes reference to the inpainted object in the synthetic observation, so that the policy is able to execute successfully.
Our approach involves changing part of the input image such as the object and background. Therefore, we specifically use Stable Diffusion (SD) inpainting, a latent text-to-image diffusion model capable of generating photo-realistic images given a text prompt.

We use CLIPort as out robot policy model. CLIPort is an end-to-end framework designed to empower robots with the ability to manipulate objects precisely while also reasoning about them using abstract concepts. It combines two essential components: the broad semantic understanding of CLIP and the spatial precision of TransportorNet. CLIPort is a language-conditioned imitation-learning agent that can perform various tabletop tasks, such as packing unseen objects and folding clothes, without the need for explicit object representations, memory, or symbolic states. This framework has been shown to be data-efficient and capable of generalizing effectively to both known and unknown semantic concepts. It can even handle multiple tasks with performance comparable to single-task policies, making it a versatile and powerful tool for robotic manipulation.
Examples of pick and place affordance predictions from ROSO in tasks from color, objects and unseen background color domain as well as real world data


The variation in generated images from Stable Diffusion (SD), such as producing diverse interpretations for prompts like "Pepsi next box," has a destabilizing effect on CLIPort's success rate as the generated "Pepsi next box" is not aligned with the CLIPort's traininig set.

@inproceedings{Miyashita2023ROSO
author = {Miyashita, Yusuke and Gahtidis, Dimitris and La, Colin and, Rabinowicz, Jeremy and Leitner, Jürgen},
title = {ROSO: Improving Robotic Policy Inference via Synthetic Observations},
journal = {ACRA},
year = {2023},
}